Tafsiri: Revolutionizing Podcast Accessibility with AI
In the realm of digital content, podcasts have emerged as a popular medium for storytelling, education, and entertainment. However, language barriers often limit the reach of these valuable resources. Recognizing this challenge, the team at ArtSciLab has embarked on an ambitious project to make their Creative Disturbance Publishers (CDP) podcasts accessible to a global audience, regardless of language. The solution? Tafsiri.

Introducing Tafsiri
Tafsiri is an AI-powered software designed to transcribe and translate CDP podcasts, which are primarily recorded in English, into any of the 100 most spoken languages in the world. This web-based application leverages Azure Cognitive Services and is powered by the Neural Machine Translation (NMT) model, enabling it to support conversations, search for podcasts, transcribe, and translate content, and return the requested podcasts with subtitles in the user’s preferred language.
Impact and Accessibility
The impact of Tafsiri is far-reaching. By breaking down language barriers, Tafsiri democratizes access to the CDP’s rich content, making it accessible to non-English speakers across the globe. This aligns with the vision of the Harry Bass Jr. School of Arts, Humanities, and Technology at The University of Texas at Dallas, which initiated the CDP project.
The Team
The development of Tafsiri is spearheaded by a team with a wealth of knowledge in AI implementation and secure coding practices.

Sir Mbwika
Lead Developer

Vinayak Jaiwant Mooliyil
Developer
Collins Mwange (Sir Mbwika) is a Cybersecurity ’25 graduate student at UT Dallas. He has over 5 years of experience in software development, systems support, and cybersecurity. Collins likes experimenting with new technologies.
Vinayak Mooliyil is a Business Analytics and AI graduate student at JSOM. He has 3+ years of experience in the IT industry and is currently transitioning to ML and Data Science having worked on IoT and Web Development projects.
Bottom Line
Tafsiri represents a significant stride in making digital content more accessible. By harnessing the power of AI, it transcends language barriers, bringing diverse audiences closer to the wealth of knowledge shared through the Creative Disturbance Publishers. The dedicated team behind Tafsiri continues to innovate, driven by the vision of a world where language is no longer a barrier to information.
Tafsiri Implementation
Implementation 1: Using Microsoft’s Neural Machine Translation (NMT) Models
We used the Microsoft Translator API (https://api.cognitive.microsofttranslator.com/), which is powered by Microsoft’s proprietary Neural Machine Translation (NMT) models, part of Azure AI services.
Microsoft developed these large language models (LLMs) for translation, separate from OpenAI’s GPT models. They are trained using deep learning techniques and optimized for multilingual translation across 100+ languages.
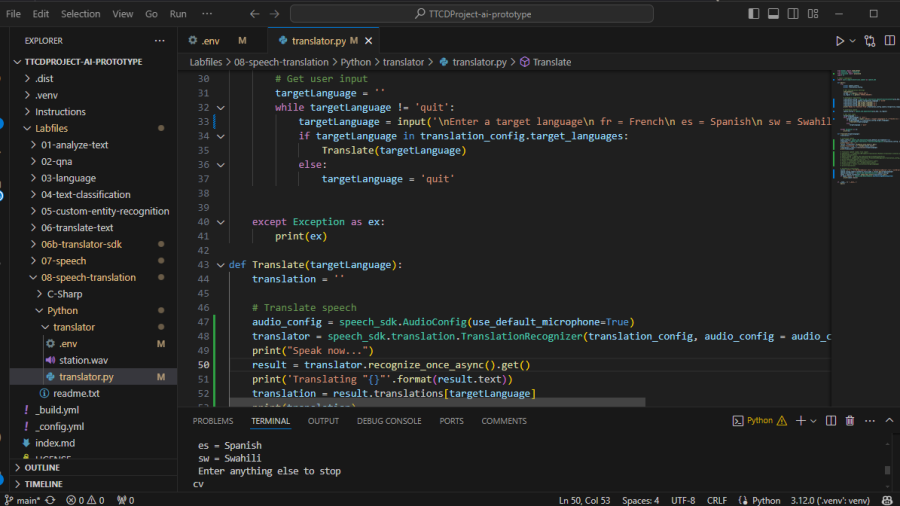

Implementation 2: Using OpenAI’s Whisper Model
Ditching the Microsoft Azure managed service Neural Machine Translation (NMT) model for open-source locally hosted options, we embarked on research to find a solution that was FREE for consumption and supported Translation from English to other languages.

The ideal solution would be free to consume and support Speech-to-Speech Translation from English to other languages. If that was not available, we would settle for a Free solution that supported Speech-to-Text (English-to-English) and Text-to-Speech (English-to-Other Languages). It could be a single model supporting the 2 steps, or two different models supporting individual steps.
2.1. Considering model=OpenAI/Whisper-base
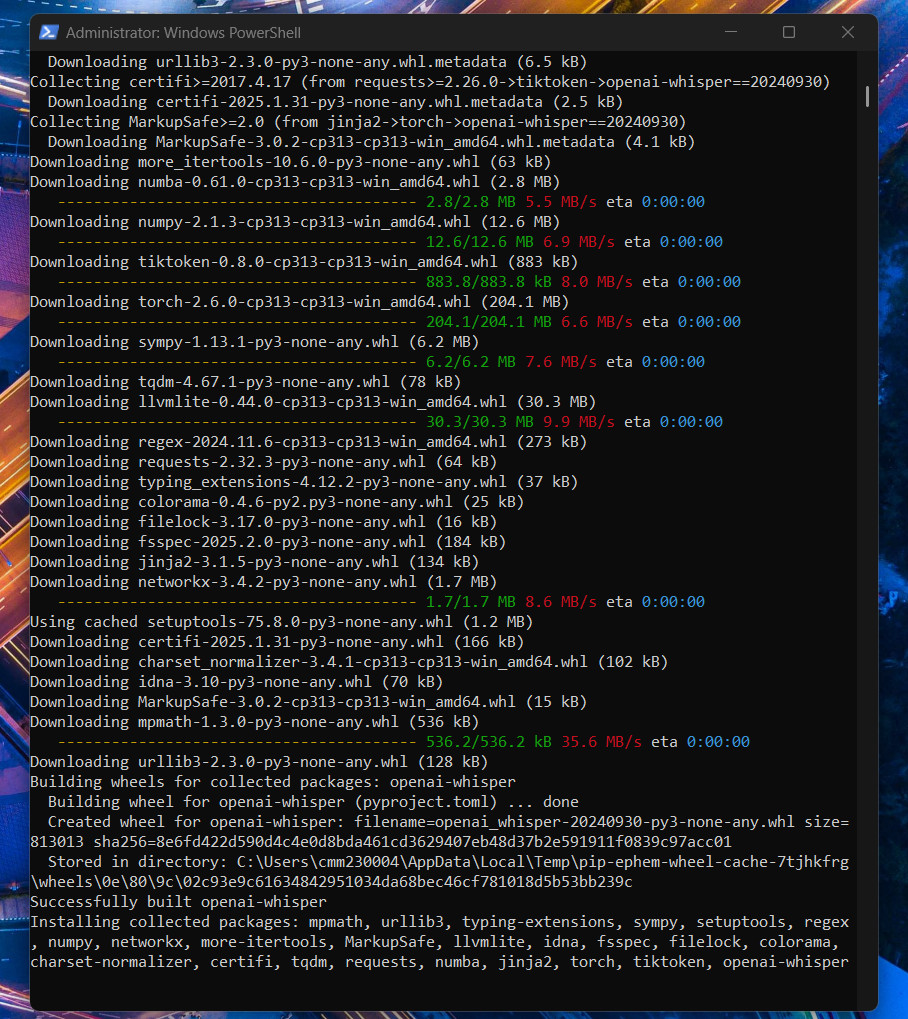
⚠️ DID NOT ADDRESS OUR PROBLEM
- Only supported Speech-to-Text translations
- Supported translation from other languages to English (reverse != True)
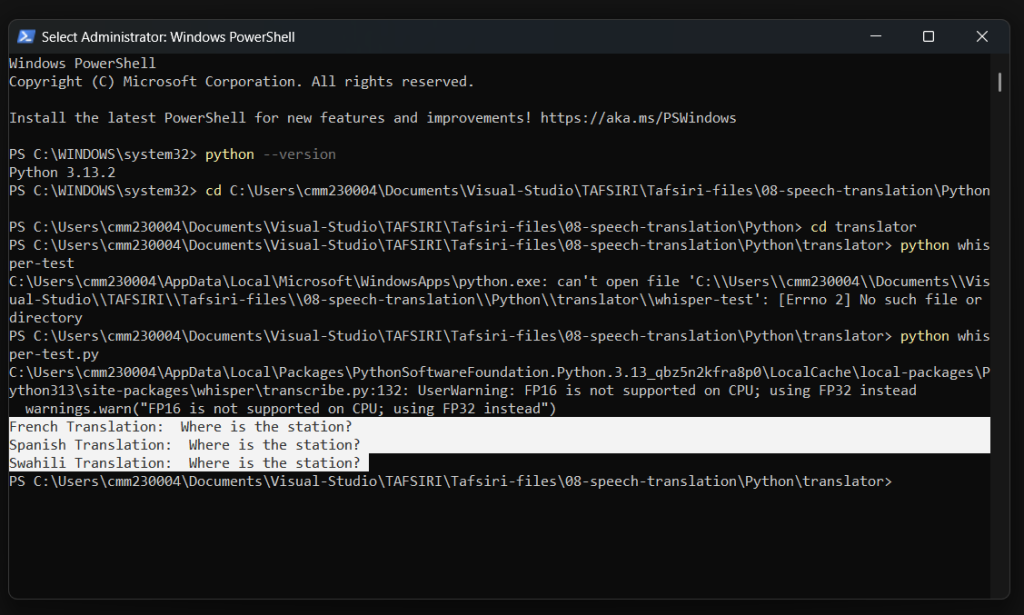
Implementation 3: Meta’s SEAMLESSM4T
Why Consider SeamlessM4T Large (v1) for Our Use Case?
SeamlessM4T supports:
- Speech-to-Speech Translation (S2ST)
Translates spoken English into speech in other languages. - Speech-to-Text (S2T)
Converts English speech to English text. - Text-to-Speech (T2S)
Converts translated text into speech in the target language.
🔹 Key Features
- Free for non-commercial use (Open-source under Meta’s research license).
- Supports many languages for both text and speech.
- End-to-end model (No need for separate STT and TTS models).
- Pretrained & downloadable for local or API use.
⚠️ Limitations
- License restrictions (Not for commercial use).
- Hardware requirements (Large model needs a strong GPU).
- Limited real-time capability (Latency depends on setup).
1️⃣ Using edge-tts (Offline Microsoft TTS)
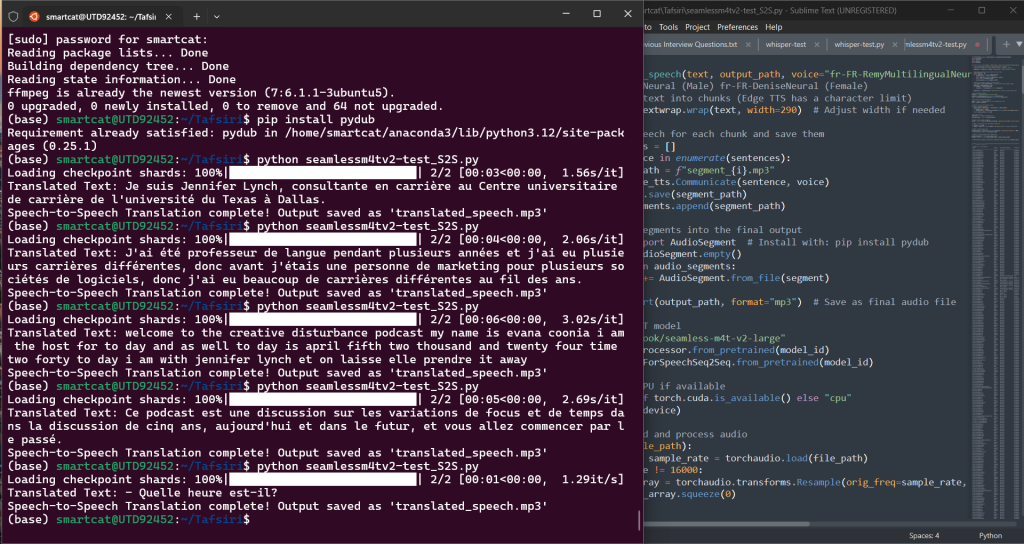
For offline TTS, installed and used edge-tts (Microsoft’s Text-to-Speech engine):
✅ Pros: Works offline, no API key needed
❌ Cons: Fewer voice options
❌ edge-tts has a character limit per request (~300 characters).
✅ Handles long text automatically (splits text into smaller chunks before sending it to edge-tts).
✅ Combines multiple audio segments into one final MP3 file.
Sample Podcast in English
Sample Podcast in French (Translated)
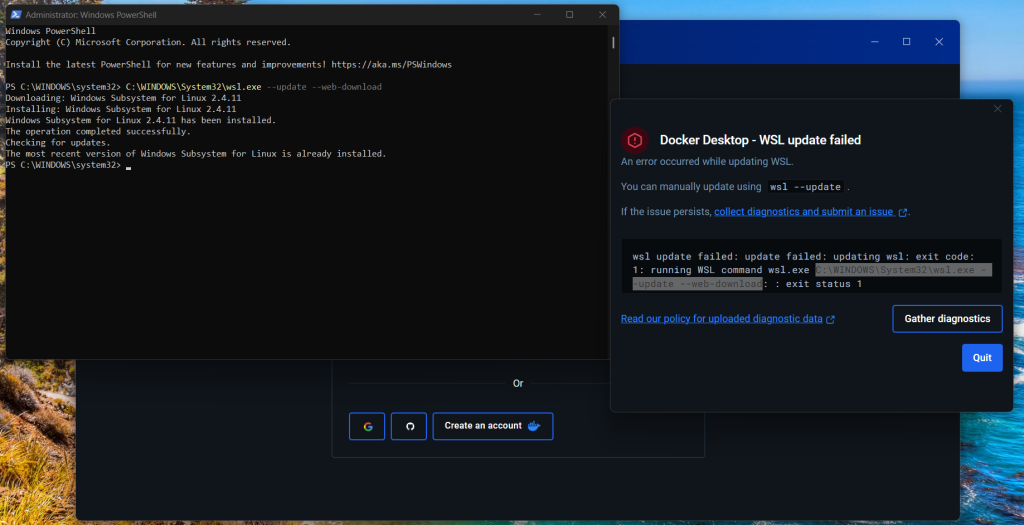
Containerization
Choosing between containerizing earlier and containerizing later, we settled for containerizing earlier. This is the analysis of both options:
1️⃣ Containerizing Before Writing Code (Early Containerization)
✅ Best for:
- Microservices-based applications
- Teams working in diverse environments
- Ensuring dependency consistency from the start
🔹 Pros:
- Developers work in the same containerized environment from day one.
- Avoids “it works on my machine” issues.
- Simplifies onboarding for new developers.
- Ensures smooth CI/CD integration.
🔸 Cons:
- Requires upfront planning for dependencies and environment setup.
- May slow down early development if requirements change frequently.
💡 Best Practice:
- Create a basic Dockerfile early with just essential dependencies.
- Use docker-compose to define services like databases.
- Update the Dockerfile as the project evolves.
2️⃣ Containerizing After Writing Code (Late Containerization)
✅ Best for:
- Small projects or prototypes
- Applications with unclear dependencies
- Teams that are new to Docker
🔹 Pros:
- Faster initial development without worrying about Docker setup.
- Less overhead when experimenting with different tech stacks.
🔸 Cons:
- Might face dependency conflicts when containerizing later.
- Debugging can be harder if the code was not designed with containerization in mind.
- Might require code changes to ensure compatibility with Docker (e.g., handling file paths, and environment variables).
💡 Best Practice:
- Use a Dockerfile-first approach for production, even if you skip it during prototyping.
- Document dependencies early to ease containerization later.
Conclusion: When Should You Containerize?
🚀 For long-term projects: Containerize early to maintain consistency.
⚡ For quick prototypes: Containerize later but plan ahead.
Moving From the Terminal to the GUI
1. Desktop GUI
To build the GUI (Graphical User Interface), we used PyQt5, a Python binding for the Qt application framework.
Why PyQt5?
- Feature-rich: Supports a variety of UI elements.
- Cross-platform: Works on Windows, macOS, and Linux.
- Multithreading support: Keeps UI responsive
2. Web GUI
React
FullStack: FastAPI, Vite + React, TailwindCSS, and SeamlessM4T v2 + edge_tts
Tafsiri full-stack technologies:
✅ FastAPI (Backend) – Manages file uploads, translation, and text-to-speech processing.
✅ Vite (Server) – is a build tool and development server with hot module replacement (HMR).
✅ React + TailwindCSS (Frontend) – Provides an intuitive UI for users.
✅ SeamlessM4T v2 (LLM Model) – Handles multilingual speech-to-text translation.
🛠 1️⃣ How These Technologies Work Together
- React Frontend (User Interface)
- Users upload audio files.
- Select the language and voice.
- Monitor translation progress via WebSockets.
- Download the translated audio file.
- FastAPI Backend
- Receives the uploaded file.
- Processes the audio using
torchaudio+SeamlessM4T v2. - Converts translated text into speech using
edge_tts. - Uses WebSockets to send real-time status updates.
- SeamlessM4T v2 (LLM)
- Converts speech from the uploaded audio file into text.
- Translates it into the selected language.
- Tailwind CSS
- Ensures a clean, responsive UI.